
1 核心作用与发展趋势
车载摄像头正在成为自动驾驶中语义能力最强的传感器。相比雷达偏重几何量、激光雷达偏重结构信息,Camera 提供的是“场景内容”本身:路面纹理、交通标志、行人姿态、车道线、光照条件等。随着深度学习模型不断演进,视觉系统的角色从识别单一物体,逐步升级为理解完整道路语义的核心。
1.1 视觉感知在ADAS体系中的定位
1.1.1 高级语义信息的唯一来源
摄像头能够解析车辆类别、行人姿态、路面材质、交通标志含义及周边建筑结构等丰富语义信息。这类高层语义特征是雷达和激光雷达等主动传感器难以提供的,也是理解环境语义结构的唯一可靠来源。
1.1.2几何推断的重要组成部分
利用单目几何推断、双目视差计算或多摄像头融合,系统可以生成深度图、路面平面模型以及障碍物的相对距离。尽管几何精度不及雷达,但在中近距离驾驶场景中,其一致性和空间分辨率通常更具优势,足以支撑大量ADAS功能。
1.1.3行为理解的核心工具
图像序列包含丰富的动态细节,如车辆转向灯状态、行人朝向、轮胎转角、步态变化等。这些细微但关键的视觉线索能够显著提升对道路参与者未来行为的预测能力,是行为理解模型的重要输入。
1.1.4 感知体系中的主导角色
在大多数量产级ADAS系统中,摄像头通常作为主传感器承担环境建模和决策的主要信息来源;毫米波雷达承担补充距离与速度测量的任务;激光雷达则依据车型定位和成本策略进行选择性配置。因此,Camera 在整体感知体系中占据核心地位。
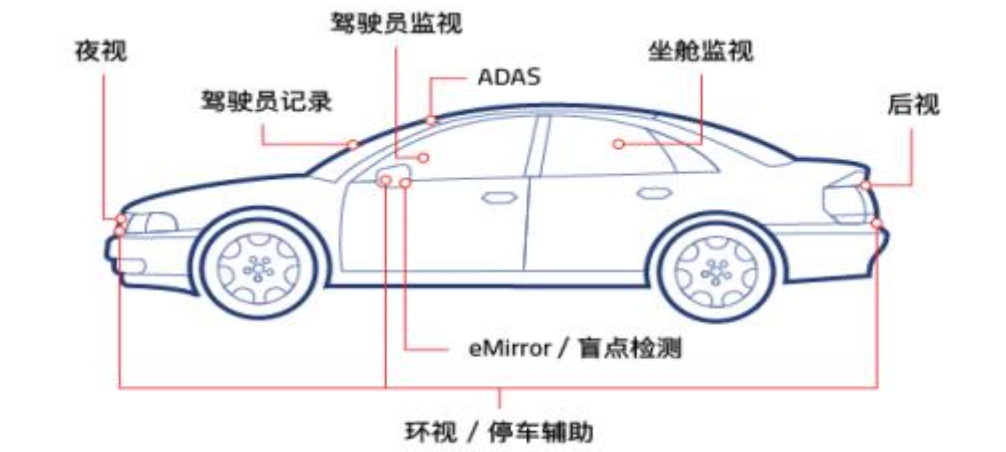
1.2 Camera 技术演进概览
1.2.1 传统视觉算法时代
这一时期的视觉感知主要依赖边缘检测、Hough 曲线拟合、模板匹配等规则驱动方法。算法结构清晰,但对光照、阴影、遮挡等环境扰动极为敏感,鲁棒性有限,难以支撑复杂道路场景下的可靠识别。
1.2.2 深度学习主导的识别时代
卷积神经网络(CNN)的普及使车辆检测、行人识别、车道线分割等核心任务的精度和泛化能力实现跨越式提升。深度学习模型能够从海量样本中自动提取稳定特征,让摄像头迅速成为成本最优、功能最全面的主力传感器。
1.2.3 空间结构重建时代
Transformer 结构、BEV(Bird’s-Eye View)表示以及单目深度网络的出现,使视觉从“二维图像识别”进化到“场景三维重建”。部分先进系统已经能够依托纯视觉感知生成统一的空间占据图和三维场景表示,为高阶感知提供结构化世界模型。
1.2.4 软件定义摄像头
随着更智能的 ISP,更高分辨率、更强 HDR 能力的硬件演进,以及端到端训练方法的普及,摄像头逐渐从传统影像硬件升级为可重构、可持续迭代的软件系统。它在多模态传感架构中承担越来越智能且更中心化的角色。
1.3 从“识别工具”到“场景语义引擎”的转变
1.3.1 从物体检测到场景理解
视觉感知不再满足于识别车辆、行人等孤立目标,而是开始理解整体场景语义,例如道路是否具备可行驶性、行人是否存在临近横穿的意图、对向车辆是否显露换道趋势。这种从目标级到场景级的升级让视觉模型能够提供更高层次的驾驶语义。
1.3.2 从被动观察到主动预测
通过分析身体姿态、轮胎转角、灯光变化及环境动态趋势,视觉系统具备了对未来几百毫秒场景演化的预测能力。对行为趋势的提前感知能显著缩短决策链路,为路径规划和风险规避争取时间。
1.3.3 从二维图像到统一空间建模
利用多摄像头协同感知、几何投影以及深度网络,视觉系统能够构建 BEV(鸟瞰图)空间表示,将二维图像信息转化为结构化三维场景。BEV 为后续的轨迹规划、避障和空间推理提供输入,使视觉在空间决策中占据更重要的位置。
1.3.4 从独立传感器到系统核心
摄像头逐渐从一个独立传感器转变为整套感知系统的主数据源。其提供的高分辨率语义、几何和时序线索成为融合感知、世界建模和行为预测等模块的基础输入,使 Camera 成为现代 ADAS 架构中的核心组件。
1.4 关键术语
ISP(Image Signal Processor)
图像信号处理链,包括降噪、去马赛克、自动曝光、颜色校正等,用于把 RAW 光学信号转化为可被算法使用的图像。
FOV(Field of View)
摄像头视野范围。大 FOV 用于环视覆盖,小 FOV 用于前视远距检测。
HDR(High Dynamic Range)
提升在逆光、夜间、隧道出口等极端场景的亮暗细节。常见方式包括多曝光/DOL-HDR。
Rolling Shutter / Global Shutter
Rolling 按行曝光,易产生形变;Global 全局曝光稳定性更高,但成本大。
BEV(Bird’s Eye View)
把图像映射成俯视坐标,是现代 3D 感知、路径规划的重要输入格式。
2 成像原理与硬件系统构成
车载摄像头的成像过程本质上是一个“从光学世界到电子信号”的转换链路。它由镜头、光学组件、图像传感器、ISP 处理流水线等部分组成。自动驾驶中的 Camera 不追求摄影级画质,而是强调:稳定、低噪声、高动态范围、高温可靠性、畸变可控以及对算法友好的成像特性。
2.1 光学成像基础
车载成像的基础是光通过镜头折射后聚焦到传感器表面。光学系统的核心任务是:尽可能让传感器在恶劣环境下获得清晰、低畸变、光照均匀的影像。由于车载摄像头必须在极端光照、振动、高温、雨雾、眩光条件下保持稳定,其光学结构往往具有更严格的设计规范。
车载光学系统通常采用定焦广角镜头,配合耐高温塑料镜片、多片式结构、抗反射涂层、红外滤光片等,形成一个高度工程化的成像链路。
2.1.1 镜头结构与焦距设计
2.1.1.1 镜头结构基于多片式广角设计
车载镜头一般包含 4–8 片非球面塑料镜片,结构紧凑,具备较大的视角范围。非球面镜片用于减少像差,提高边缘清晰度,适应大 FOV(如 120°)所需的光线折射稳定性。
2.1.1.2 焦距决定视野宽度与远距能力
焦距(f)定义光学系统的成像放大能力。
短焦距(例如 f≈2.4 mm) → 大广角,用于环视、泊车。
中等焦距(f≈6–8 mm) → 平衡距离与视野,用于前视主摄像头。
长焦距(>12 mm) → 用于特定的远距检测,但在量产车中较少使用。
焦距越短,视野越广,但远距离目标的像素密度下降;焦距越长,远处清晰,但视野变窄。前视摄像头常采用 50–60° 的水平视场角以兼顾 80–150 m 的目标识别能力。
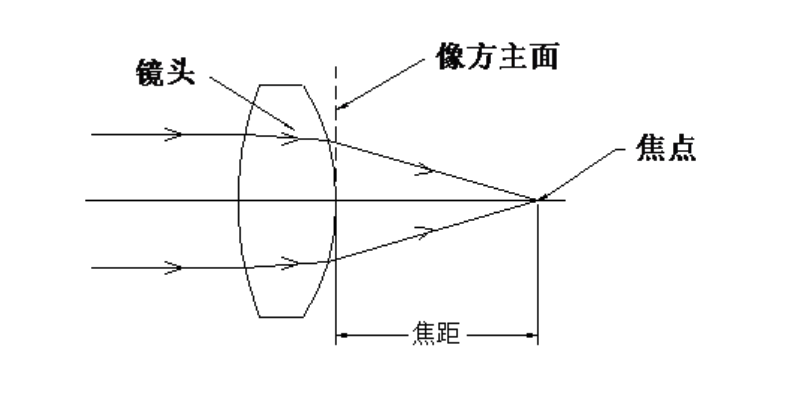
2.1.1.3 固定焦距而非变焦设计
车载摄像头不会采用可变焦镜头,因为会带来机械结构、可靠性和成本问题。所有成像距离适配都通过分辨率、ISP、算法补偿来实现。
2.1.2 FOV、畸变和光圈对成像的影响
2.1.2.1 FOV 决定感知覆盖范围
FOV(Field of View)是镜头的水平/垂直视角。
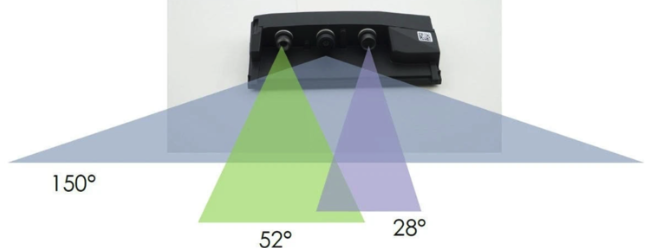
大 FOV(如 120°–150°) → 适合环视、盲区检测,但畸变更强,边缘像素有限。
中等 FOV(如 50°–80°) → 前视摄像头的主流配置,远近兼顾。
小 FOV(20°–40°) → 适合远距监控或狭窄区域高精度识别。
FOV 与分辨率共同决定“每度像素数”(pixel per degree, PPD),进而影响检测距离能力。
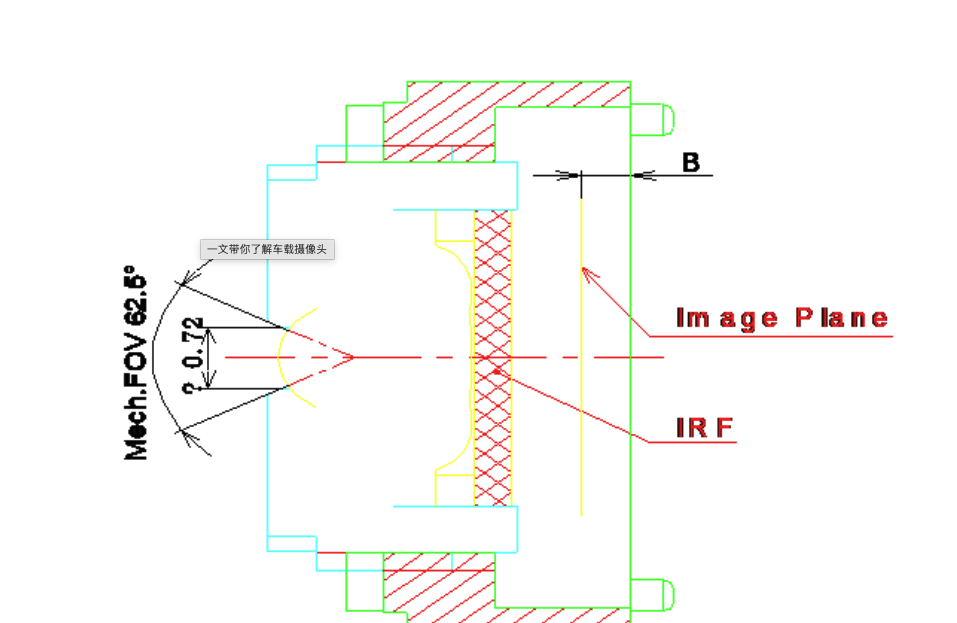
FOV角度理论上是越大越好,比如做隐藏式行车记录仪DVR的摄像头,这个时候就需要记录到的两边的图像越宽越好,越方便信息的完整性。FOV的角度直接影响到最终摄像头测距的距离,所以这个FOV角度也是最好根据摄像头的实际应用来选择。
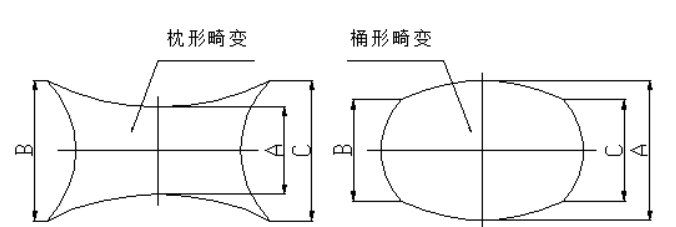
2.1.2.2 畸变是广角镜头的固有特性
广角镜头通常产生桶形畸变(Barrel Distortion)。
在自动驾驶中,畸变不是画质问题,而是“空间精度问题”。
畸变越大,几何还原难度越高;映射到 BEV 时需要更强的畸变模型校正。
车载系统使用标定模型(通常基于针孔+畸变系数)补偿畸变,确保图像能精确地投影到空间坐标。
2.1.2.3 光圈决定进光量与景深
光圈大小以 F-number 表示,例如 F2.0、F2.4、F2.8。
小光圈(更大 F 值) → 景深更大,适合车载中全距离清晰成像。
大光圈(更小 F 值) → 进光量更大,夜间性能好,但景深变浅。
车载摄像头几乎都使用较小光圈(如 F2.4~F3.0)以保证从 3 m 到 100 m 区间目标都保持稳定清晰。
2.1.3 光线、曝光、噪声来源机制
2.1.3.1 曝光是光线控制的核心
曝光由“快门时间 + 感光度(ISO)”共同决定。
曝光时间越长 → 图像更亮,但易产生运动模糊,尤其是高速行驶场景。
ISO 越高 → 亮度提升,但噪声显著增加。
车载系统通常采用短曝光、多曝光(DOL-HDR)与 ISP 降噪结合的方式,在高速状态下尽量避免模糊。
2.1.3.2噪声来源于传感器物理限制
车载图像常见几类噪声:
光子噪声:光的粒子特性导致的随机性,是物理极限噪声。
热噪声:传感器高温环境下电荷随机跳动产生,在夏季尤为严重。
读出噪声:从像素读取电子信号过程产生的干扰。
噪声越高,目标边缘越模糊,算法精度越低。因此高温噪声抑制(特别是 85°C 环境下)是车规传感器的重要指标。
2.1.3.3 逆光与夜间是最困难的光照场景
逆光会导致前景过暗、背景过曝;夜间光源点产生强烈高光。车载系统依赖:
多曝光合成(HDR)
光圈固定下的动态曝光控制
ISP 的局部亮度增强
以保持车道线、车辆轮廓、行人等关键特征的可识别性。
2.2 Sensor 图像传感器
2.2.1 CMOS Sensor 工作原理
汽车摄像头普遍采用 CMOS(Complementary Metal-Oxide Semiconductor)图像传感器,其核心任务是将光信号转换为可处理的电信号。每个像素(Pixel)都是一个独立的光电转换单元,通过光电二极管(Photodiode)吸收光子并产生电荷。系统通过逐行读取(Rolling Shutter)或全局读取(Global Shutter)方式,将像素电荷转换为数字化数据。
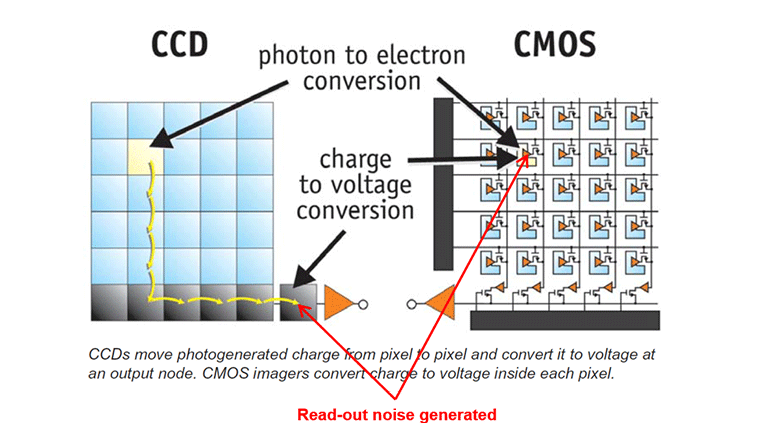
在汽车应用中,CMOS Sensor 不仅承担成像任务,还提供诸多额外能力,如自动曝光、黑电平校准、温度补偿和防闪烁控制(Flicker Mitigation)。这些能力直接决定了相机在不同光照条件下的稳定性。
一个典型 CMOS Sensor 的信号路径包含以下步骤,从光到数据的转换在此过程中完成:
光子进入像素并产生电子。
电荷在像素内积累并形成与光强度成比例的信号。
逐行或全局方式读取像素电荷。
通过模拟信号链(Reset、Source Follower、Column ADC)转为数字信号。
形成 RAW 图像输出。
2.2.2 像素结构
CMOS 像素结构通常由三大要素组成:光电二极管(PD)、微透镜(Micro Lens)和颜色滤光片(CFA, Color Filter Array)。这些结构共同决定了图像质量、噪声水平和光敏能力。
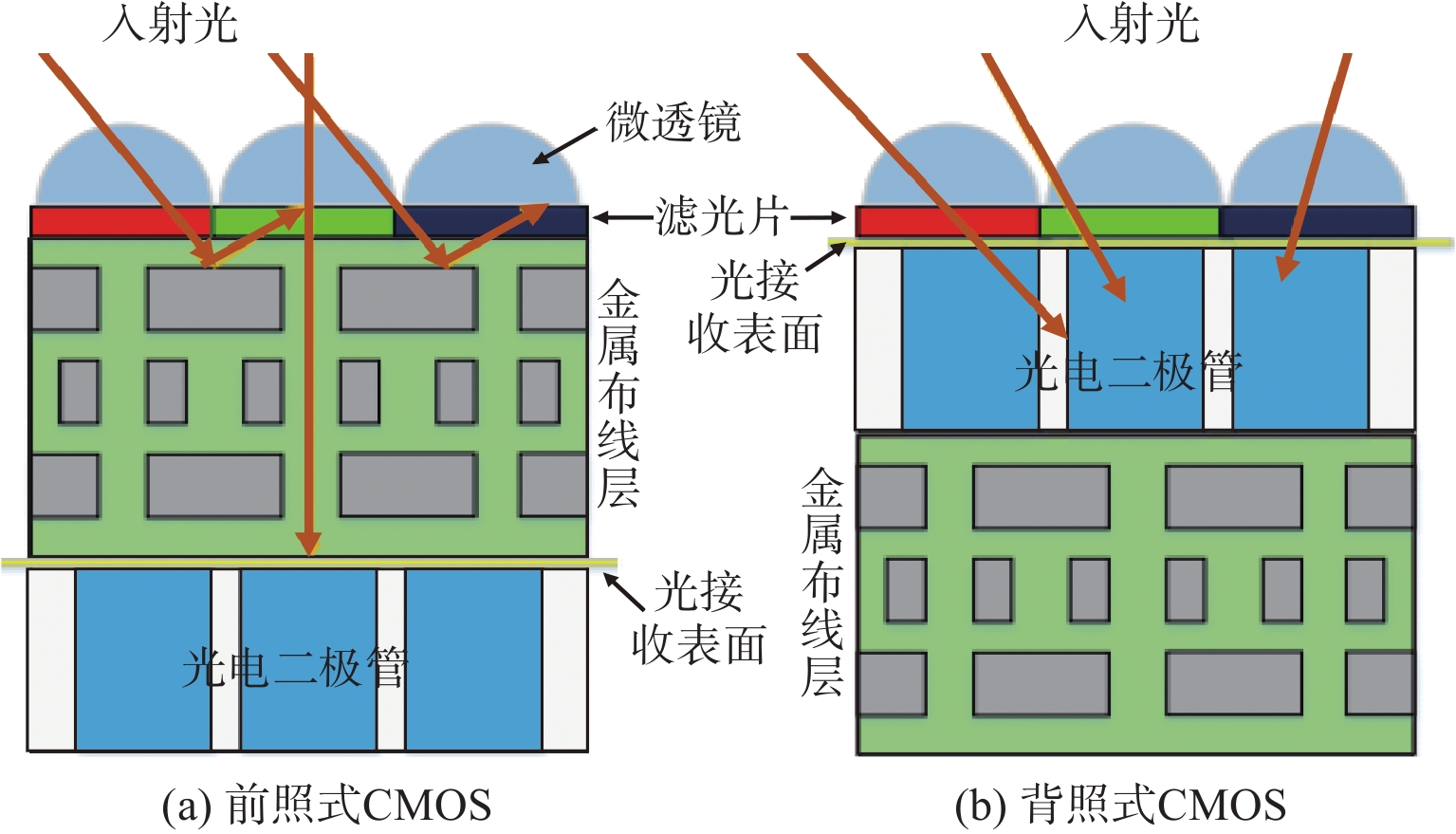
2.2.2.1 光电二极管(PD)
这是像素的光电转换核心,用于收集光子产生电荷。PD 的尺寸称为 像素尺寸(Pixel Pitch),其大小直接影响光敏度和信噪比(SNR)。汽车摄像头中 pixel 多为 2.0–3.0 µm,以兼顾分辨率与光敏度。
2.2.2.2 微透镜(Micro Lens)
微透镜是覆盖在每个像素上的微小透镜,用于将尽可能多的光聚焦到 PD 区域,提高量子效率(QE, Quantum Efficiency)。在汽车应用中,因光线入射角广,微透镜需具备高偏轴透过率(High Chief Ray Angle)。
2.2.2.3 颜色滤光片(CFA)
常见的是 Bayer 阵列(RGGB),用于实现彩色成像。部分夜视摄像头会使用单色 Sensor,以获得更高光敏度。汽车摄像头常加入 NIR(近红外)补光或使用 NIR 优化的 CFA,提高夜晚性能。
2.2.2.4 像素电路结构(3T/4T/5T)
汽车 Sensor 多为 4T 或 5T 架构,能实现低噪声、全局复位(Global Reset)和行曝光控制,为 HDR 等能力打基础。
2.2.3 动态范围(HDR)获取方式
汽车环境的亮度分布极其极端,例如:黑暗隧道与强光出口、逆光行驶、太阳直射路面。为了准确捕获亮部和暗部的信息,CMOS Sensor 需要具备高动态范围(HDR,High Dynamic Range)能力,通常需要 120 dB 以上。
HDR 获取方式主要有以下三类:
2.2.3.1 多重曝光(Multi-Exposure HDR)
通过同时输出多种曝光的帧(Short/Long/Very-Short),再进行合成。这是汽车摄像头最常用方案,因为可提供极高的动态范围。
优点:动态范围大、细节丰富。
缺点:高速运动导致对齐困难,可能产生 Ghosting(鬼影)。
2.2.3.2行内 HDR(In-Pixel HDR / DOL HDR)
每行像素在单帧内分别获取多次曝光。这种方式减少时间差,因此运动伪影更少。
优点:低 Ghosting,高速行驶场景友好。
缺点:Sensor 复杂度高,对 ISP 要求高。
2.2.3.3 Dual Conversion Gain(DCG,高低增益切换)
像素通过高增益与低增益同时读取信号,分别捕捉暗部与亮部。汽车 Sensor 中 DCG 往往与其他 HDR 方案组合使用,例如 DCG + Multi-Exposure。
优点:抑制噪声,提升暗光表现。
缺点:仅依靠增益无法提供极高 HDR,需要组合方案。
3 摄像头感知算法体系解析
摄像头感知算法的演进,本质上是从“像素理解”到“空间理解”的递进过程。早期只关注图像中有什么(What),随后开始关注物体之间的关系(Where),再到如今强调三维结构、可通行空间和未来行为(How & What next)。这一章将围绕量产视觉感知体系展开,从 2D 任务、3D 任务,到多目标跟踪与端到端感知。
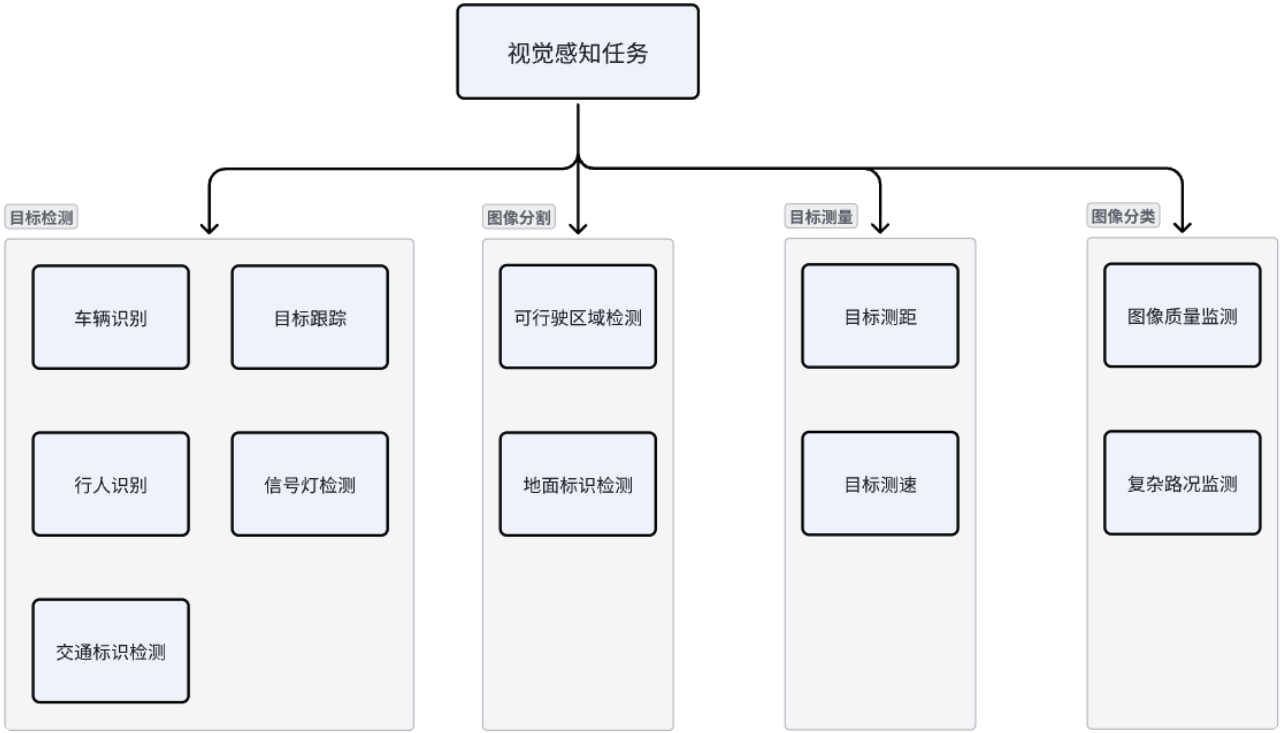
3.1 2D 视觉任务
2D 视觉任务仍然是摄像头感知体系的基础组成部分。所有高层任务(BEV、深度估计、行为预测)都依赖稳定的 2D 语义特征,因此其可靠性直接决定整套系统的上限。
3.1.1 分类(Classification)
分类任务的目标是判断图像中是否存在某种类型的对象,例如车辆类型、交通标志类别或行人姿态状态。传统卷积网络(CNN)依靠局部卷积提取纹理、边缘与颜色等低层特征,再逐层组合成高层语义。
在 ADAS 场景中,分类的关键不在于单张图片的准确性,而在于 稳定性与可泛化能力,包括:
不同光照、天气、夜间场景下的稳健特征提取
远距小目标的分类能力(典型难点)
类别粒度的平衡,例如区分 sedan / SUV,还是更关注“车辆 vs 非车辆”
随着 Transformer 架构出现,自注意力机制让分类模型可以同时关注局部与全局区域,使小目标和复杂背景下的识别能力进一步提升。
3.1.2 物体检测(Detection)
物体检测是 ADAS 场景中最核心的视觉任务之一,其目标是输出目标的类别与位置(Bounding Box)。

检测模型经历了三个重要阶段:
两阶段检测器(如 Faster R-CNN)
先生成候选区,再分类与回归,精度高但速度相对较慢。
单阶段检测器(YOLO、RetinaNet)
将检测视为端到端回归问题,速度快,易于上车部署。
基于 Transformer 的检测器(DETR 系列)
去掉 anchor 与 NMS,通过注意力机制直接生成目标集合,结构更统一。
量产 ADAS 中最关键的指标是 推理延迟(Latency)、稳定性 和 小目标召回率。例如 100m 远距行人、摩托车或虚线车道旁的小交通锥都是典型挑战。
3.1.3 语义与实例分割(Segmentation)
分割任务负责输出像素级语义信息,是车道线检测、可行驶区域提取(FreeSpace)以及交通标识地面标记识别的重要基础。
语义分割:给每个像素分配语义类别,如道路、草地、车辆。
实例分割:进一步区分同类物体,如两个行人、三辆车各为独立实例。
在道路场景中,分割模型必须处理:
车道线在雨夜被遮挡、磨损或光斑覆盖
地面结构剧烈变化,如上坡、下坡与匝道
自然场景中的“不规则边界”,如树影与反光水洼
Transformer-based segmentation 在对细节边界的识别上明显优于传统 CNN。
3.1.4 车道线检测与 Road Marking 识别
车道线检测是驾驶辅助系统中最关键的功能之一,传统基于边缘的算法已完全被深度网络替代。
车道线检测模型通常输出结构化数据,包括:
多条车道线的多项式参数或 spline 参数
Road Marking 的类别,如虚线、实线、箭头、停止线
曲率、朝向、消失点位置(用于道路几何重建)
在高等级 ADAS 中,例如车道级导航(LKA/L3),车道线检测与 BEV 建模高度耦合,需要在 BEV 空间中输出统一结构,使规划模块能够直接消费结构化几何信息。
3.2 3D 视觉任务
3D 视觉任务的核心目标是从二维图像中恢复真实世界的三维结构,包括深度、方位、尺度与空间关系。相比 2D 任务只关注“是什么”,3D 任务需要回答“物体在哪里”“地面形状如何”“空间能否通行”等问题。这一部分是现代 ADAS 感知体系的关键升级点。
3.2.1 单目深度估计原理
单目深度估计试图从单帧图像恢复场景深度,这是一个病态的几何问题,因为单目图像本质缺乏绝对尺度信息。然而,利用几何规律、统计规律和神经网络学习,可以得到稳定的伪深度(Pseudo-depth)。
单目深度估计的发展路径可分为两个阶段:
3.2.1.1 基于几何和结构先验(Geometry-based)
早期方法依赖摄像头成像模型的基本几何约束,例如:
透视投影规律:远处物体在图像中更小
消失点结构:道路纹理依赖透视线聚合
地平线约束:大部分道路场景中的平面结构固定
这种方式能捕捉粗略深度结构,但对复杂光照、遮挡和非结构化场景表现有限。
3.2.1.2 基于深度神经网络(Deep Learning-based)
如今,深度估计主要依赖卷积网络和 Transformer,通过海量数据学习场景统计特性。训练方式有两类:
监督学习(Supervised):以激光雷达、双目深度等作为真实深度 GT。
自监督学习(Self-supervised):通过视差一致性、时序一致性、光度一致性构建损失,无需真实深度标注。
在 ADAS 中,单目深度的价值包括:
提供连续深度图,用于语义融合和 BEV 变换
弥补雷达稀疏点云的覆盖不足
在中近距离提供平滑的地面与障碍物结构
虽然单目深度无法达到激光雷达精度,但在 BEV 网络中与其他任务联合训练后,其几何一致性已具备量产价值。单目深度估计试图从单帧图像
3.2.2 立体视觉(Stereo)视差与双目前端系统
Stereo(立体视觉)利用两个固定基线距离的摄像头,通过视差(Disparity)计算获得深度,是最传统也是最符合物理原理的视觉深度测量方式。
Stereo 系统的核心包括以下三个部分:
3.2.2.1 视差计算
双目系统通过特征匹配或代价体积(Cost Volume)构建方式计算左右图的像素偏移量。早期使用 SGM(半全局匹配),现代多采用基于 3D 卷积的深度网络(如 PSMNet)。
3.2.2.2 双目前端(Front-end)
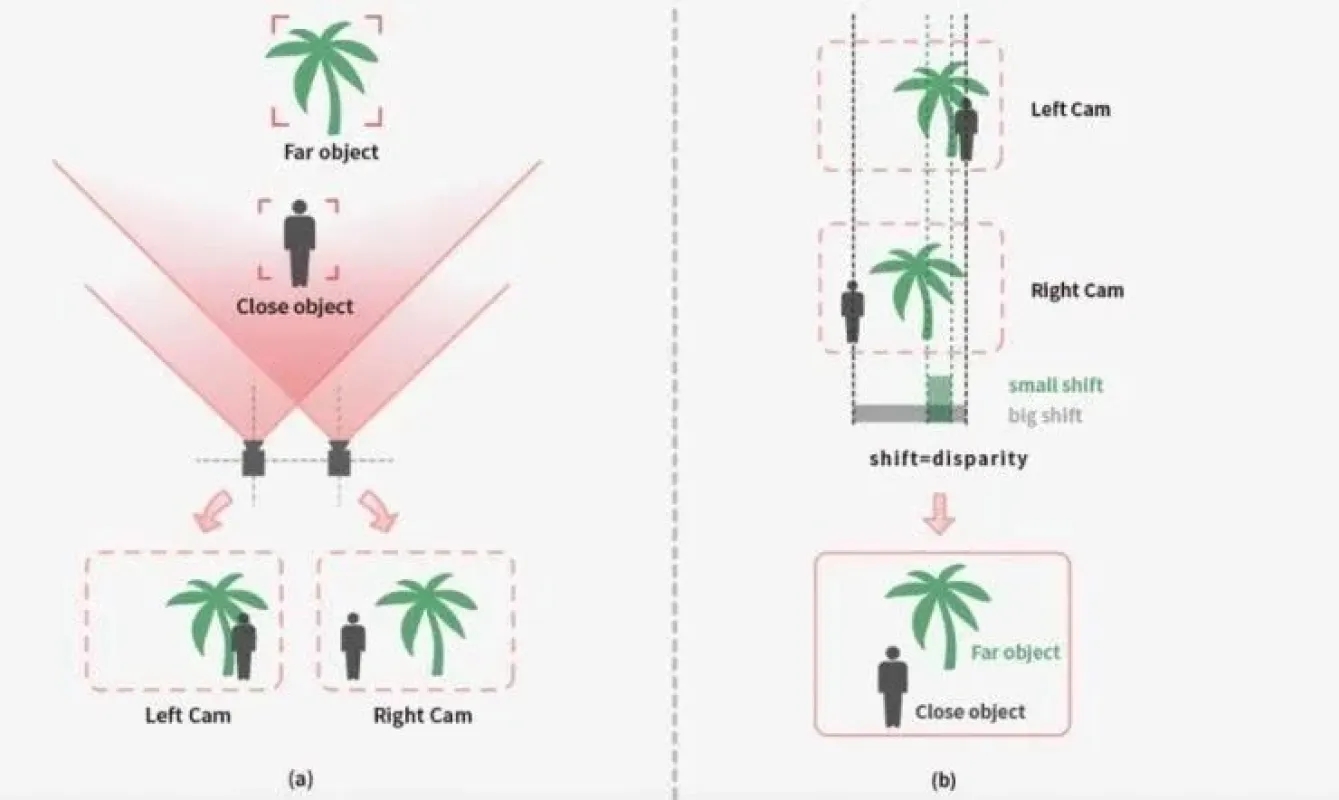
双目前端的作用是:
图像同步与曝光一致性
基线距离的机械确保(通常 10–30 cm)
几何标定与畸变校正
这些因素直接影响视差的稳定性。
3.2.2.3 性能特性
Stereo 的特点在于:
中近距离精度高,特别适合车距估计
对纹理依赖性强,低纹理区域(如白墙、夜间无反射路面)误差会明显上升
深度随距离平方衰减,远距性能不如激光雷达或毫米波雷达
在 L2/L2+ 系统中,Stereo 常与单目深度联合使用,通过学习增强纹理弱区间的表现。
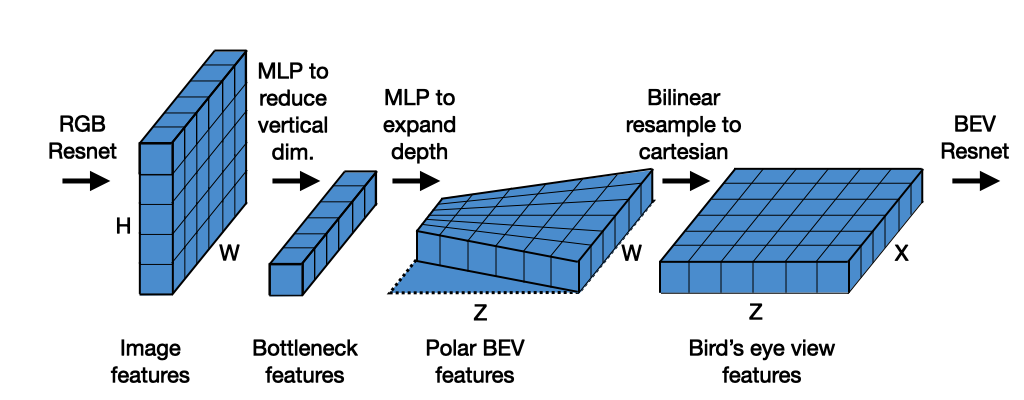
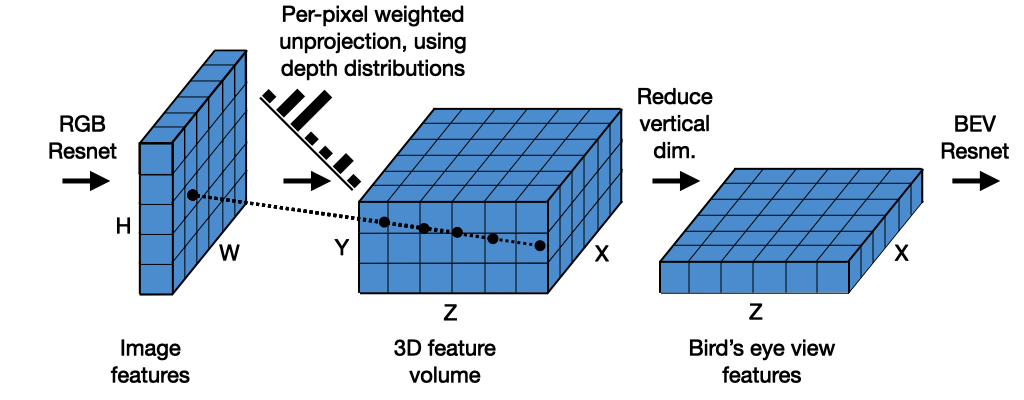
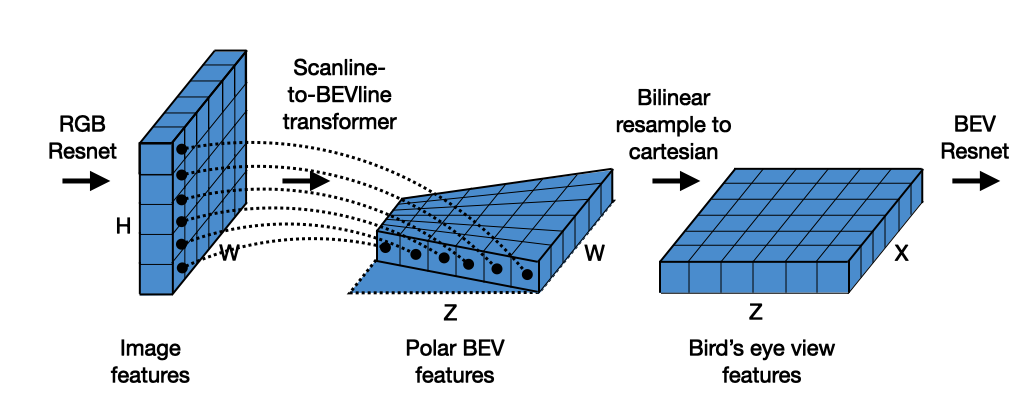
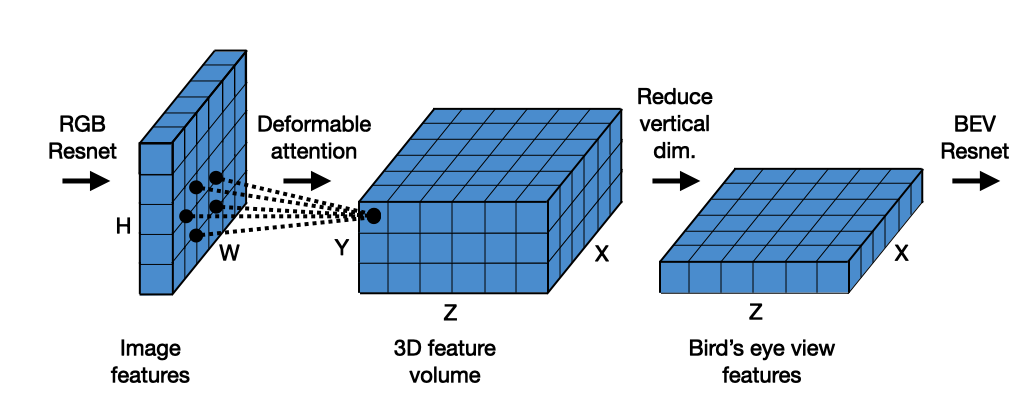
3.2.3 BEV(鸟瞰图)构建与空间重建
BEV(Bird’s-Eye View)是近年来视觉感知体系最重要的突破之一,通过将图像特征投影到统一鸟瞰图空间,使视觉从“图像理解”升级为“空间理解”。
T. Roddick 和 R. Cipolla:《使用金字塔占用网络从图像预测语义地图表示》,CVPR 2020。
J. Philion 和 S. Fidler:《Lift, Splat, Shoot:通过隐式三维反投影对任意相机阵列图像进行编码》,ECCV 2020。
A. Saha、O. M. Maldonado、C. Russell 和 R. Bowden:《将图像转换为地图》,ICRA 2022。
Z. Li、W. Wang、H. Li、E. Xie、C. Sima、T. Lu、Q. Yu 和 J. Dai:《BEVFormer:通过时空 Transformer 从多相机图像学习鸟瞰图表示》,ECCV 2022。
BEV 建模体系通常包含三步:
3.2.3.1 特征提取(Image Encoder)
CNN 或 Transformer 提取多尺度语义特征,包含形状、纹理、边界与深度线索。
3.2.3.2 特征投影(View Transformation)
从图像坐标到 BEV 坐标的关键步骤,主要有三种实现方式:
几何投影(Lift-Splat):利用深度分布将像素特征抬升到 3D 网格。
端到端学习投影(LSS / BEVFormer):通过注意力机制直接学习图像到 BEV 的映射。
深度辅助投影:引入单目深度或 Stereo 深度增强几何准确性。
3.2.3.3 BEV 空间理解(BEV Decoder)
在 BEV 上执行下游任务:
FreeSpace(可通行区域)
Lane Graph(车道图像素化/矢量化)
动态物体 BEV 检测与轨迹预测
占用网络(Occupancy Network)构建周围空间体素
BEV 的优势在于:
多摄像头可无缝融合
规划模块可直接消费 BEV 的结构化空间数据
模型在 BEV 上具有几何一致性,更易处理遮挡问题
BEV 正在成为视觉感知体系的统一“世界坐标”,其重要性逐渐等同甚至超过传统 2D 任务。
3.3 视觉跟踪与多目标关联
视觉跟踪(Tracking)负责在连续帧之间保持对同一物体的身份一致性,而多目标关联(Multi-Object Association)在更高层面确保场景中所有物体的轨迹结构化输出。两者共同构成摄像头感知在时域的核心能力,为后端预测(Trajectory Prediction)、决策规划(Decision Making)提供连贯的动态环境模型。
3.3.1 单目标与多目标跟踪的差异
单目标跟踪(SOT)专注于跟踪一个已知目标,常见于传统视觉任务;而自动驾驶必须处理几十个动态目标,因此更多依赖多目标跟踪(MOT)。
MOT 的挑战来自遮挡、相似外观目标的密集分布以及摄像头的动态视角变化。
3.3.2 以检测为基础的 Tracking-by-Detection 流程
当前主流系统采用 Tracking-by-Detection(TbD)范式:
检测模块输出物体框 → 特征抽取 → 匹配与关联 → 轨迹更新。
这一流程的关键在于数据关联算法,例如匈牙利算法(Hungarian Algorithm)配合 IoU 匹配,或以目标外观 embedding 进行特征相似度关联。
3.3.3 外观特征与运动模型
为了提升遮挡情况下的鲁棒性,外观 embedding(如 Re-ID 特征)在自动驾驶中被引入,与运动模型共同参与匹配。
常见运动模型包括卡尔曼滤波(Kalman Filter)与扩展卡尔曼滤波(EKF),以稳定预测目标在下一帧的空间位置和速度,实现更稳健的轨迹连续性。
3.3.4 时序一致性的工程挑战
在车载摄像头中,时序不稳定是常见问题。
帧率波动、不同摄像头不同步、目标的短时消失(如被前车遮挡)都会削弱跟踪精度。
工程上通常引入轨迹生命周期管理机制,包括:
初始确认帧数(Confirm Frames)
缺失容忍度(Max Age)
轨迹切换概率过滤(Switching Penalty)
这些机制确保系统既不过度冒进创建新轨迹,也不会因为短暂失配而轻易丢失目标。
3.4 端到端视觉感知(E2E)趋势与挑战
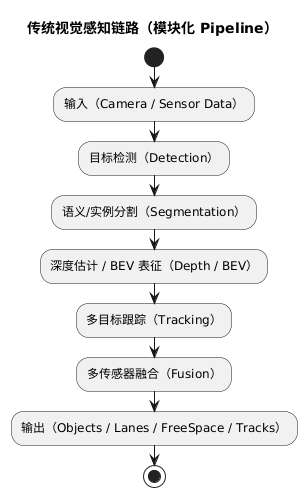
随着深度学习的扩展,视觉感知逐渐从模块化 pipeline 向端到端(End-to-End)架构迁移。
E2E 感知目标是通过统一网络完成特征抽取、空间感知、跟踪甚至部分预测任务,从而减少模块割裂带来的误差传递。
3.4.1 端到端感知的核心思想
传统感知链路包括:检测 → 分割 → 深度 / BEV → 跟踪 → 融合
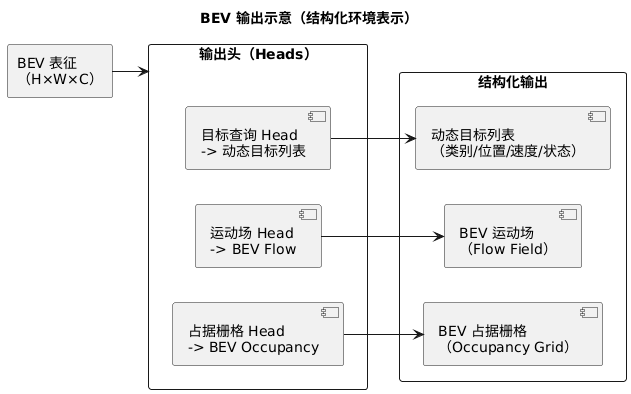
E2E 的目标是让网络直接输出结构化环境表示,例如 BEV Occupancy、BEV Flow 或动态对象列表。
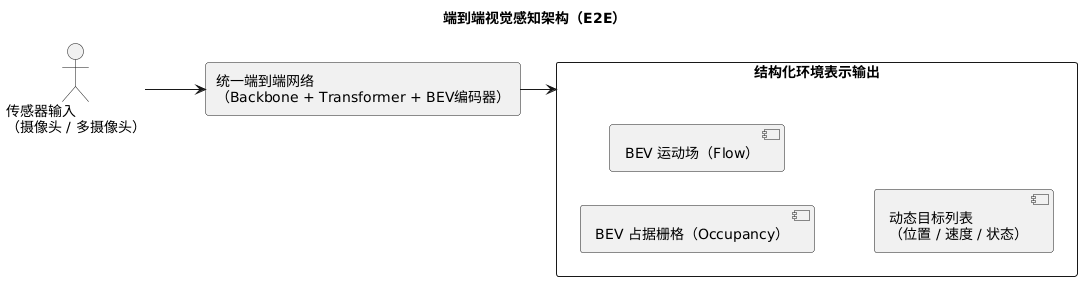
Transformer 类架构(如 BEVFormer、PETR)推动了 BEV E2E 感知的进一步普及,依靠自注意力机制在时间维度构建一致性的空间理解。
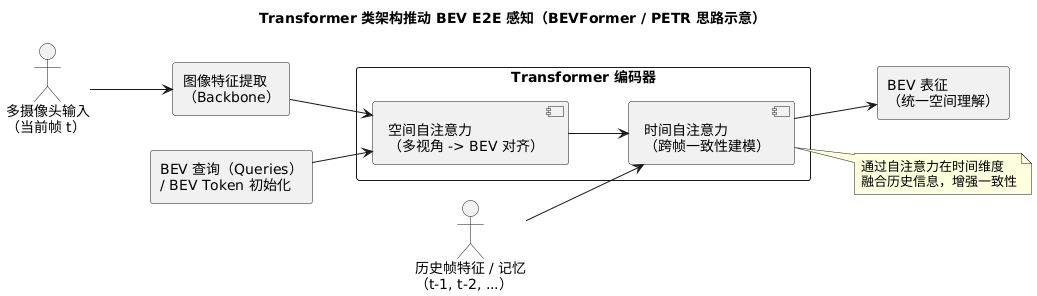
BEV 输出的示意
3.4.2 优势:统一特征空间与全局关联
端到端系统最大优势在于:
特征空间统一,减少冗余计算
时间/空间关联可由一个网络内部完成
系统整体可训练(End-to-End Training)
模块边界减少,误差不再逐步堆积
这使其在复杂场景下的稳定性优于传统逐级 pipeline。
3.4.3 挑战:算力压力、数据标注与可解释性
E2E 感知也带来显著挑战:
巨大算力需求:Transformer 在高分辨率下的计算复杂度通常呈平方级增长,车规芯片需要大量优化。
训练数据要求高:全链路监督需要更多带时序与空间标签的数据,成本高昂。
可解释性弱:系统端到端优化使模块内部不可分解,给调试与安全认证带来额外压力。
工程部署复杂性高:量化(INT8)、带宽、延迟等限制均会影响 E2E 模型表现。
因此,行业普遍认为短期内 E2E 会与模块化系统共存,而非迅速取代。
3.5 算法延迟、吞吐和算力设计(GFLOPS / Frame-rate)
摄像头感知系统在车端受强约束:有限算力、严格时间预算和热设计(Thermal Design Power,TDP)限制都决定了算法可使用的模型规模。
3.5.1 延迟(Latency)
对于前视摄像头,单帧延迟通常要求 40–80 ms 以内。
延迟主要由以下部分构成:
图像 ISP 处理时间
前端图像预处理
深度神经网络推理时间
后处理包括 NMS、关联、轨迹管理等
在高速场景下,延迟过大会导致车辆对动态目标的实时性下降,从而降低规划的可控性。
3.5.2 吞吐(Throughput)
吞吐通常以 FPS(Frame per Second)衡量。
典型自动驾驶感知摄像头工作在 25–30 FPS,少部分 BEV 模型优化后能稳定在 20 FPS 以上。
吞吐对硬件带宽与 GPU/加速器的计算能力提出直接要求,尤其在多摄像头融合场景下(如 8V 方案)压力更明显。
3.5.3 算力设计(GFLOPS / TOPS)
模型规模与硬件算力息息相关。
例如:
单目 YOLO 级别网络通常在 10–50 GFLOPs
BEV Transformer 系统往往超过 150–400 GFLOPs
多目 E2E 感知系统则可能达到 > 1 TOPS 级别
工程团队需在精度与实时性之间寻找平衡:
利用模型剪枝(Pruning)
网络结构自动搜索(NAS)
特征金字塔分辨率压缩
INT8 量化提升 2–4 倍推理速度
3.5.4 延迟与稳定性的系统级关注点
摄像头 ISP、图像传输链路和调度系统同样影响整体延迟。
如在 SoC 上,调度器若未合理分配推理优先级,可能出现:
瞬时“卡顿”
算子等待导致 pipeline 堵塞
多摄像头互相影响导致延迟堆积
因此算力设计不仅是模型问题,也是系统工程问题。
评论
留下你的阅读回音